순위 관련 함수
* RANK
- 동일한 값에 대해서는 동일한 순위를 부여 (1,2,2,4)
- OVER절과 함께 사용
- ex) RANK() OVER (PARTITION BY partition_expression ORDER BY sort_expression [ASC | DESC], ...);
-> PARTITION BY: 특정 기준에 따라 파티션을 나누고 각 파티션 내에서 순위를 부여합니다.
-> ORDER BY: 순위를 매길 때 사용할 정렬 기준을 지정합니다. ASC는 오름차순, DESC는 내림차순을 나타냅니다.
* DENSE_RANK
- 동일한 순위를 하나의 등수로 간주 (1,2,2,3)
- ex) DENSE_RANK() OVER (PARTITION BY partition_expression ORDER BY sort_expression [ASC | DESC], ...);
- RANK와 달리 동일한 값이 있을 경우에도 중복된 순위를 부여하지 않음
* ROW_NUMBER
- 동일한 값이라도 고유한 순위 부여 (1,2,3,4)
- 동일한 값이 있더라도 각 행에 번호를 부여함
- 정렬 순서에 따라 행에 일련번호를 부여하며, 정렬 순서를 지정하지 않으면 결과는 임의로 정렬된 순서로 나타납니다.
집계 관련 함수
- SUM : 파티션별 윈도우의 합을 구할 수 있다.
- MAX, MIN : 파티션별 윈도우의 최대,최소값을 구할 수 있다.
- AVG : 원하는 조건에 맞는 데이터에 대한 통계 평균 값.
- COUNT : 지정된 열이나 행의 개수를 세는데 사용.
그룹 내 행 순서 함수
- FIRST_VALUE() : 윈도우 내에서 정렬된 순서에 따라 첫 번째 행의 값을 가져옵니다.
- LAST_VALUE() : 윈도우 내에서 정렬된 순서에 따라 마지막 행의 값을 가져옵니다. 이 함수는 윈도우의 끝까지 갔을 때만 값을 반환하므로 주의가 필요합니다.
- LAG() : 현재 행 이전의 행에 있는 값을 가져옵니다. LAG() 함수의 인자로는 가져올 행의 상대적인 위치가 들어갑니다.
-> LAG(column2, 1, 0) == column2의 바로 이전 행을 반환, 바로 이전행이 null이라면 0 반환
- LEAD() : 현재 행 이후의 행에 있는 값을 가져옵니다. LEAD() 함수의 인자로는 가져올 행의 상대적인 위치가 들어갑니다.
-> LAG와 동일
비율 관련 함수
- RATIO_TO_REPORT() : 윈도우 내에서 특정 값이 전체 값 중에서 차지하는 비율을 계산합니다.
- PERCENT_RANK() : 정렬된 결과에서 현재 행의 상대적인 순위를 백분율로 계산합니다.
PERCENT_RANK()의 계산 방식은 다음과 같습니다
- n을 결과 집합의 행 수라고 할 때, PERCENT_RANK() 값은 (R - 1) / (n - 1)입니다.
- 여기서 R은 현재 행의 순위를 나타냅니다. (순위는 1부터 시작)
- 따라서, 첫 번째 행의 PERCENT_RANK() 값은 0이 되고, 마지막 행의 값은 1이 됩니다.
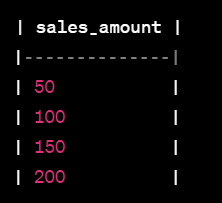
PERCENT_RANK() 함수는 다음과 같이 계산됩니다:
- 50: 0.0 (0 / 3)
- 100: 0.333 (1 / 3)
- 150: 0.666 (2 / 3)
- 200: 1.0 (3 / 3)
결과적으로 PERCENT_RANK()는 누적 상대적인 순위를 나타냅니다.
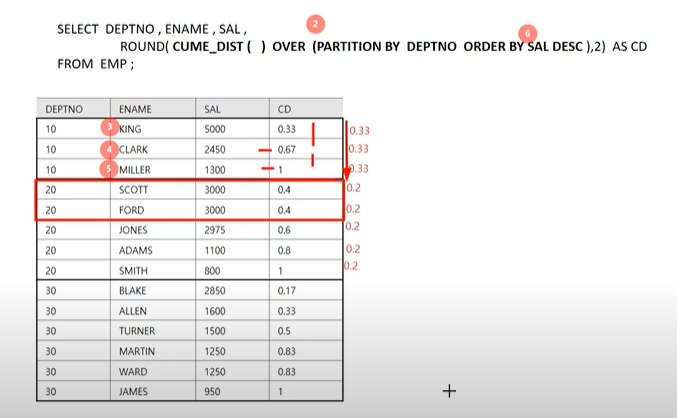
- CUME_DIST() : 누적 분포 함수로, 현재 행까지의 값이 전체 값 중에서 어느 정도의 누적 비율을 차지하는지 계산합니다.
- NTILE() : 정렬된 결과를 동일한 개수의 버킷 또는 타일로 나누어 각 행이 속하는 타일을 지정합니다. 예를 들어, NTILE(4)는 데이터를 4개의 그룹으로 나눕니다.

-> 총 14행을 4개로 나누면 몫은 3이고 나머지는 2가 나온다. 나머지 2들은 각각 상위 그룹에 1개씩 나눠진다. 그래서 4,4,3,3, 으로 4개의 타일로 나누어졌다.
'SQLD' 카테고리의 다른 글
| SQLD 개념정리 (절차형 SQL) (0) | 2023.11.12 |
|---|---|
| SQLD 개념정리 (DCL) (1) | 2023.11.12 |
| SQLD 개념정리 (GROUPING) (0) | 2023.11.09 |
| SQLD 개념정리 (그룹함수) (3) | 2023.11.09 |
| SQLD 개념정리 (View) (0) | 2023.11.08 |