절차형 SQL
- SQL문의 연속적인 실행이나 조건에 따른 분기처리를 이용하여 특정 기능을 수행하는 저장 모듈을 생성할 수 있다. Procedure, User Defined Function, Trigger 등이 있음.
- 분기, 반복이 가능한 모듈화된 프로그램. DBMS에서 직접 실행됨
- 프로시저(Procedure), 사용자 정의 함수(User Defined Function), 트리거(Trigger)
- [Oracle] PL/SQL
- [SQL Server] T-SQL
- PL/SQL은 여러 SQL문장을 BLOCK으로 묶고 한번에 BLOCK전부를 서버로 보내기 때문에 통신량을 줄여서 응용프로그램의 성능응 향상시킴.
PL/SQL 특징
1. Block 구조로 되어있어 각 기능별로 모듈화 가능
2. 변수 상수, 등을 선언하여 SQL 문장 간 값을 교환
3. IF, LOOP 등의 절차형 언어를 사용하여 절차적인 프로그램이 가능하도록 한다.
4. DBMS 정의에러나 사용자 정의 에러를 정의하여 사용할 수 있다.
5. PL/SQL은 Oracle에 내장되어 있으므로 호환성 좋음.
6. 응용 프로그램의 성능을 향상시킨다.
7. Block 단위로 처리 -> 통신량을 줄일 수 있다.
T-SQL (Microsoft SQL Server)
- T-SQL은 Microsoft SQL Server에서 사용되는 확장된 SQL 언어로, 저장 프로시저, 트리거, 함수, 뷰 등을 작성하는 데 사용됩니다. T-SQL은 특히 Microsoft SQL Server에 특화된 기능과 문법을 지원합니다.
* T-SQL의 주요 특징
- 저장 프로시저 및 함수: T-SQL을 사용하여 데이터베이스에 저장 프로시저와 함수를 작성할 수 있습니다.
- 트랜잭션 제어: T-SQL은 트랜잭션을 명시적으로 제어할 수 있는 문법을 제공합니다.
- 예외 처리: T-SQL에서는 TRY...CATCH 구문을 사용하여 예외 처리를 수행할 수 있습니다.
- 윈도우 함수: 데이터 분석 및 윈도우 함수를 사용하여 복잡한 쿼리 및 집계를 수행할 수 있습니다.
- XML 지원: T-SQL은 XML 데이터를 다루는 데 필요한 기능을 지원합니다.

프로시저(Procedure)
- 주로 DML을 사용해 주기적으로 진행해야되는 작업을 저장
- 별도의 호출을 통해 실행
- CREATE OR REPLACE Procedure 문으로 프로시저를 생성
=> OR REPLACE : 기존에 같은 이름의 프로시저 있으면 무시하고 새로운 내용으로 덮어씀
- 작업의 결과를 DB에 저장 (트랜잭션 처리) < - > (사용자 정의 함수는 결과 리턴)
- BEGIN ~ END문 사이에 작업 영역 생성 (1 - 3은 섞어서 사용하고, 4번만 마지막에 작성)
1) 조건/반복 영역
2) SQL을 사용해 데이터 관리하는 영역
3) 예외 처리 영역
4) 트랜잭션 영역 (작업 결과를 실제로 반영하거나 취소하는 영역)
- 프로시저 내부의 절차적 코드는 PL/SQL 엔진이 처리
=> 일반적인 SQL 문장은 SQL 실행기가 처리
- 프로시저 실행
* EXECUTE 프로시저명 (파라미터);
* EXEC 프로시저명 (파라미터);
* CALL 프로시저명 (파라미터);

- 프로시저 삭제
* DROP Procedure 프로시저명;

사용자 정의 함수(UDF)
- 사용자 정의 함수(User-Defined Function, UDF)은 데이터베이스 사용자가 정의한 함수로, 특정 연산을 수행하고 값을 반환하는 데 사용됩니다.
- 데이터베이스 쿼리나 다른 함수 내에서 호출될 수 있으며, 코드의 재사용성과 가독성을 증가시키는 데 도움이 됩니다.
- 사용자 정의 함수를 사용하면 비즈니스 로직이나 반복적인 연산을 함수로 캡슐화하여 코드의 재사용성을 높일 수 있습니다.
- 프로시저와 구조 비슷
- 함수 호출 시 특정 값을 돌려 받을 수 있음 => 리턴값(반환값)
- 작업 결과를 호출한 쿼리문에 돌려줌 <=> 프로시저는 DB에 저장
* PL/SQL에서의 사용자 정의 함수
- 형식
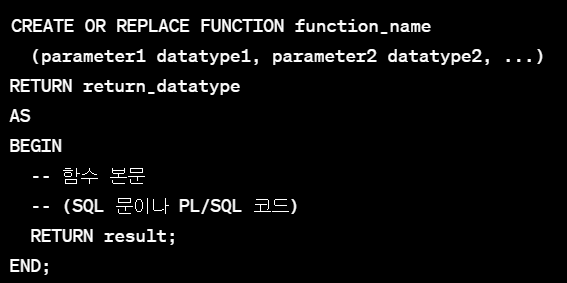
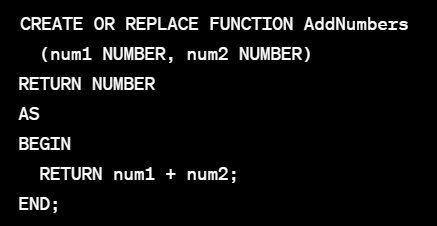
- ex) 두 숫자를 더하는 간단한 함수
* T-SQL에서의 사용자 정의 함수
- 형식
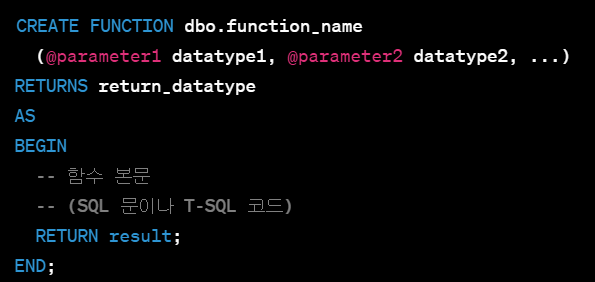
- ex) 두 숫자를 더하는 간단한 함수

트리거 (Trigger)
- 트리거(Trigger)는 데이터베이스에서 특정 이벤트가 발생할 때 자동으로 실행되는 일련의 SQL문 또는 PL/SQL 블록입니다.
- 데이터베이스의 상태를 모니터링하고, 이벤트에 응답하여 추가적인 작업을 수행할 수 있도록 해줍니다. 주로 데이터의 무결성 유지, 로깅, 자동화된 작업 등을 위해 사용됩니다.
- 자동으로 실행되기 때문에 리턴값, 매개변수 없음, 커밋 등도 없음 (TCL로 트랜잭션 제어 X)
- 트리거는 데이터베이스에서 다양한 이벤트에 반응하도록 설정할 수 있습니다. 일반적으로 트리거는 다음과 같은 이벤트에서 실행됩니다.
1) INSERT : 새로운 레코드가 삽입될 때
2) UPDATE : 기존 레코드가 수정될 때
3) DELETE : 레코드가 삭제될 때
4) AFTER 또는 BEFORE : 트리거가 이벤트를 처리하기 전에 또는 이후에 실행
* 트리거의 기본 구조
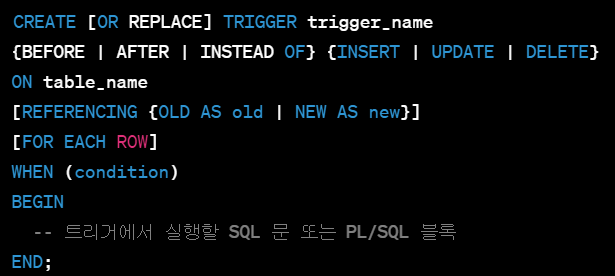
- trigger_name : 트리거의 이름을 지정합니다.
- BEFORE, AFTER, INSTEAD OF : 트리거의 실행 시점을 지정합니다.
- INSERT, UPDATE, DELETE : 트리거가 반응할 이벤트를 지정합니다.
- ON table_name : 트리거가 활성화될 테이블을 지정합니다.
- REFERENCING : 트리거에서 사용할 OLD 및 NEW 별칭을 정의합니다.
- FOR EACH ROW : 각 행에 대해 트리거가 실행될지 여부를 지정합니다.
- WHEN (condition) : 트리거가 실행될 조건을 지정합니다.
ex) employees 테이블에 새로운 레코드가 삽입될 때 실행되는 트리거
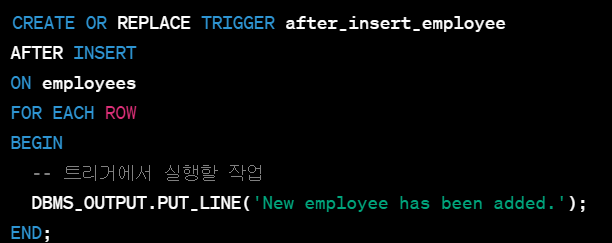
-> 이 트리거는 employees 테이블에 새로운 레코드가 삽입되고 나서 실행되며, "New employee is being added."라는 메시지를 출력합니다.
프로시저와 트리거의 차이점

'SQLD' 카테고리의 다른 글
| SQLD 개념정리 (JOIN 수행 원리) (1) | 2023.11.14 |
|---|---|
| SQLD 개념정리 (SQL 최적화 기본 원리) (0) | 2023.11.13 |
| SQLD 개념정리 (DCL) (1) | 2023.11.12 |
| SQLD 개념정리 (윈도우 함수) (0) | 2023.11.10 |
| SQLD 개념정리 (GROUPING) (0) | 2023.11.09 |