조인의 종류
* Nested Loop JOIN (NL Join)
- 두 개의 테이블을 조인할 때 사용되며, 보통 내부 조인(inner join)에서 많이 사용됩니다.
- 조인 컬럼에 적당한 인덱스가 있어서 자연조인(Natural Join)이 효율적일때 유용하다.
- NL Join은 프로그래밍에서 사용하는 중첩된 반복문과 유사한 방식으로 조인을 수행한다.
- 반복문의 외부에 있는 테이블을 선행테이블 또는 외부테이블(Outter Table)이라고 하고, 반복문의 내부에 있는 테이블을 후행테이블 또는 내부테이블(Inner Table)이라고 한다.
- 결과 행의 수가 적은 테이블을 조인 순서상 선행 테이블로 선택하는 것이 전체 일량을 줄임. 조인이 성공하면 바로 조인 결과를 사용자에게 보여줌으로 온라인 프로그램에 적당(OLTP 환경).
- Outer Table(Driving Table)의 조인 데이터 양이 성능에 매우 중요한 요인.

-> 서브쿼리 앞이 EXISTS일 경우 "SEMI JOIN", NOT EXISTS일 경우 "ANTI JOIN"
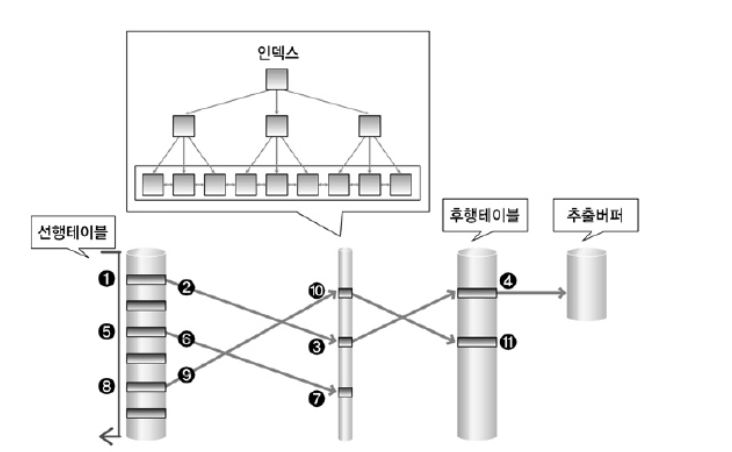
- 장점
1) 조인 조건의 선택도가 높은 경우, 내부 루프에서 빠르게 일치 행을 찾을 수 있습니다.
2) 작은 테이블과의 조인에서 효과적입니다.
- 단점
1) 대용량의 테이블에 대해 비효율적일 수 있습니다. 특히 외부 테이블의 레코드 수에 비례하여 성능이 감소할 수 있습니다.
2) 인덱스를 사용할 수 없거나 효율적으로 활용되지 못하는 경우에는 성능 문제가 발생할 수 있습니다.
* Sort Merge Join
- Sort-Merge Join은 입력 테이블이 이미 정렬되어 있고, 대량의 데이터에 대한 조인이 필요한 경우에 유용합니다.
- 주로 스캔하는 방식으로 데이터를 읽음. 조인 컬럼 인덱스 없어도 사용가능 -> 단, 성능이 떨어질 수도 있음
- 일반적으로 내부 조인에 사용됨.
- Non-EQUI JOIN
- 조인 컬럼을 기준으로 데이터를 정렬하여 조인을 수행한다. NL Join은 주로 랜덤 액세스 방식으로 데이터를 읽는 반면, Sort Merge Join은 주로 스캔 방식으로 데이터를 읽는다.
- Sort Merge Join은 랜덤 액세스로 NL Join에서 부담이 되던 넓은 범위의 데이터를 처리할 때 이용되던 조인 기법이다.
- Driving Table(Outer Table == 선행테이블)의 개념이 중요하지 않은 조인 방식이다.
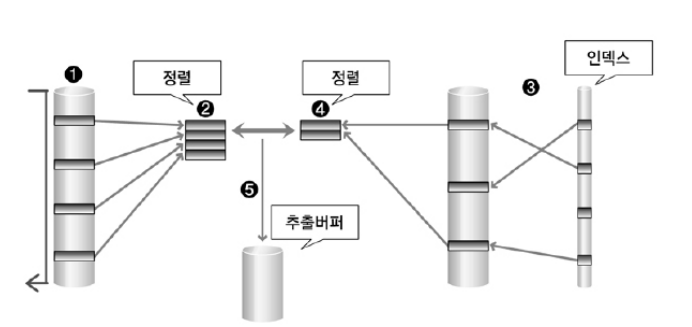
- 장점
1) 입력 테이블이 정렬되어 있다면 효과적으로 동작합니다.
2) 대량의 데이터에 대한 조인에서 효과적입니다.
- 단점
1) 정렬 오버헤드: 정렬 작업에는 비용이 발생하므로, 이미 정렬된 데이터에 대해서만 효과적입니다.
2) 메모리 요구 사항: 대용량 데이터의 경우 메모리 요구 사항이 높을 수 있습니다.
* Hash Join
- Hash Join은 NL Join의 랜덤 액세스 문제점과 Sort Merge Join의 문제점인 정렬 작업의 부담을 해결 하기 위해서 대안으로 등장하였다.
- 두 테이블 간의 조인을 수행하는 데에 활용이 되고, 해시 함수를 사용하여 조인 조건에 맞는 행을 신속하게 찾아내는 특징이 있습니다.
- 조인을 수행할 테이블의 조인 컬럼을 기준으로 해쉬 함수를 수행하여 서로 동일한 해쉬 값을 갖는 것들 사이에서 실제 값이 같은지를 비교하면서 조인을 수행한다.
- '='로 수행하는 동등 조인(Equal Join)에서만 사용할 수 있다.
- 결과 행의 수가 적은 테이블을 선행 테이블로 사용하는 것이 좋다.
- Driving Table(Outer Table == 선행테이블)이 성능에 매우 중요한 요인
- 인덱스가 존재하지 않는 경우에만 사용 가능
- 해시 테이블의 key컬럼에 중복값이 없을 수록 성능에 유리
- Hash Join은 특히 큰 테이블과 작은 테이블 간의 조인에서 효과적입니다. 그러나 메모리 제약이 있는 경우, 또는 데이터 분포가 불균일한 경우에는 성능이 저하될 수 있습니다.

- 장점
1) 메모리 내에서 수행되기 때문에 작은 테이블을 메모리에 로드하여 빠르게 조인이 가능합니다.
2) 데이터의 순서나 정렬 여부와 무관하게 동작합니다.
- 단점
1) 해시 충돌(Collision)이 발생할 수 있으며, 이는 성능 저하를 가져올 수 있습니다.
2) 큰 테이블이 메모리에 저장할 수 없는 경우 디스크 I/O가 발생하여 성능이 저하될 수 있습니다.
* 각각의 Join의 차이점

'SQLD' 카테고리의 다른 글
| SQLD 실행계획 실행순서 (0) | 2023.11.14 |
|---|---|
| SQLD 개념정리 (SQL 최적화 기본 원리) (0) | 2023.11.13 |
| SQLD 개념정리 (절차형 SQL) (0) | 2023.11.12 |
| SQLD 개념정리 (DCL) (1) | 2023.11.12 |
| SQLD 개념정리 (윈도우 함수) (0) | 2023.11.10 |