옵티마이저와 실행계획
- 옵티마이징 : 최적화 한다.
- 옵티마이저 : 옵티마이징을 수행, 성능을 가장 유리한 방향으로 이끄는 역할 수행. 즉, 최적의 실행방법, 실행계획(Execution Plan)을 짠다.
- 동일 SQL문에 대해 실행계획이 달라도 쿼리의 실행 결과는 항상 같아야 한다.
- 실행 계획 구성 요소
* 조인 순서 (Join Order)
* 조인 기법(조인 방법) (Join Method)
* 액세스 기법=액세스 방법 (Access Method)
* 최적화 정보 (Optimization Information)
* 연산 (Operator)
* 질의 처리 예상 비용 (Cost)

규칙 기반 옵티마이저
- 규칙(우선순위)을 기반으로 실행계획을 작성
-> 실행계획을 생성하는 규칙을 이해한다면 누구나 실행계획을 비교적 쉽게 예측 가능하다.
- 데이터베이스 쿼리의 실행 계획을 생성하는 데 사용되는 전통적인 최적화 방법 중 하나입니다.
- 조인 순서 결정 시 : 조인 컬럼 인덱스의 존재 유무가 판단 기준
-> 조인 컬럼에 대한 인덱스가 양쪽에 존재 : 우선순위 높은 테이블이 먼저 수행(Driving)
-> 한쪽만 인덱스 존재 : 인덱스 없는 테이블이 선행
-> 둘 다 인덱스 없음 : FROM절의 뒤에 나열된 순서로 테이블이 선행
-> 우선순위가 동일 : FROM절에 나열된 테이블의 역순으로 선행 테이블 선택
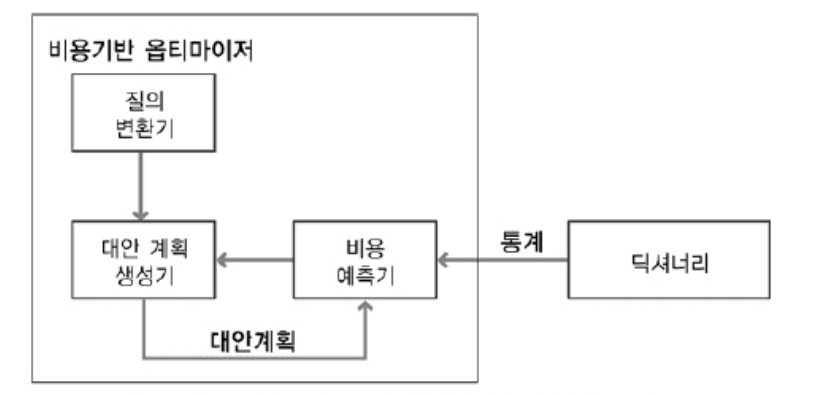
비용 기반 옵티마이저
- 비용(예상되는 소요시간, 자원 사용량)이 가장 적은 실행계획을 선택하는 방식
-> 비용에 따라 Full Scan이 유리하다고 판단할 수도 있음.
- 규칙 기반 옵티마이저 단점 극복을 위해 출현
- 다양한 객체 통계정보와 시스템 통계정보 등을 활용
- 질의 변환기 : 사용자가 작성한 SQL문을 처리하기에 보다 용이한 형태로 변환하는 모듈
- 대안 계획 생성기 : 동일한 결과를 생성하는 다양한 대안 계획을 생성하는 모듈
-> 대안 계획 : 연산 적용순서 변경, 연산 방법변경, 조인 순서 변경 등으로 생성
- 비용 예측기 : 생성된 대안 계획의 비용을 예측하는 모듈
-> 모든게 다 정확해야 함 (계산식, 예측, 분포도 등)
-> 비용은 주로 I/O 비용(디스크에서 읽기/쓰기), CPU 비용, 메모리 사용 등을 고려합니다.
- 비용 기반 옵티마이저는 테이블과 인덱스에 대한 통계 정보를 사용하여 실행 계획을 평가합니다. 이를 통해 각 테이블이나 인덱스의 크기, 카디널리티, 데이터 분포 등을 고려하여 비용을 예측합니다.
- 여러 테이블 간의 조인에서 어떤 조인 전략을 사용할지 결정합니다. 가능한 조인 전략에는 루프 조인, 해시 조인, 병렬 조인 등이 있습니다.
- Oracle, Microsoft SQL Server, PostgreSQL, MySQL 등과 같은 주요 RDBMS들은 대부분 비용 기반 옵티마이저를 사용합니다. 이를 통해 쿼리 성능을 향상시키고 최적의 실행 계획을 선택하여 데이터베이스 작업을 최적화할 수 있습니다.
SQL 처리 흐름도
- SQL 내부적 처리 절차를 시각적으로 표현한 것. -> 실행시간을 알 수 없음
- 인덱스 스캔, 테이블 전체 스캔 등과 같은 액세스 기법을 표현
- 성능적인 측면도 표현 가능

인덱스
- 일종의 오브젝트(Object)임. 조회만을 위한 오브젝트.
- 기본 인덱스(Primary Key) == UNIQUE & NOT NULL
- 인덱스가 생성되면 테이블과 매핑된 또다른 테이블(=인덱스)가 생성된다 라고 생각하면 쉬움
-> 그 테이블은 인덱스 컬럼을 기준으로 Sorting 되어 저장되기 때문에 검색 시 매우 빠름
-> 인덱스로 먼저 원하는 데이터를 찾은 후, 기존 테이블 매핑된 곳 가서 데이터를 꺼내는 방식
- 주로 WHERE, ORDER BY 절에서 자주 쓰이는 컬럼을 인덱스로 지정
- SELECT 속도 증가, INSERT, UPDATE 속도 저하(데이터 삽입 시 인덱스도 조정해야 하기 때문에)
-> INSERT, DELETE작업과 다르게 UPDATE 작업에선 부하가 없을 수도 있다.(몇개반 바꾸면 되기때문)
- 랜덤 액세스 : 인덱스를 스캔하여 테이블로 데이터를 찾아가는 방식. 매우 많은 양의 데이터를 읽을 경우, 인덱스 스캔보다 FULL 스캔이 더 효율적
-> 랜덤 액세스 부하가 큼
BLOCK(블록)
- 인덱스는 해당 테이블의 블록에 주소를 가지고 있음
- 블록 : 데이터가 저장되는 최소 단위, 테이블의 데이터들이 ROW 행 단위로 저장되어 있음
인덱스 종류
- 단일 인덱스 : 단일 컬럼으로 구성
- 결합 인덱스 : 여러 컬럼을 묶어 결합 인덱스로 구성
-> 결합하는 컬럼의 순서가 매우 중요
-> 인덱스 생성 시 아래의 컬럼을 맨 앞 순서에 배치
1) '=' 조건(동등조건)으로 많이 쓰는 컬럼이 앞에 오는게 좋음
2) BETWEEN 처럼 범위 지정하는 컬럼이 그 다음으로 오는게 좋음
3) ID 처럼 분별력 높은 컬럼이 그 다음으로 오는게 좋음

* 트리 기반 인덱스
- 트리 기반 인덱스(Tree-Based Index)는 데이터베이스에서 검색 속도를 향상시키기 위해 사용되는 인덱스 유형 중 하나입니다.
- 대표적으로 B-트리(B-Tree)와 B+트리(B+ Tree)가 트리 기반 인덱스의 예시입니다. 이러한 트리 기반 인덱스는 데이터의 효율적인 검색과 정렬을 위해 사용됩니다.
- RDBMS에서 가장 일반적인 인덱스는 B-Tree 인덱스
- '='로 검색하는 일치 검색(Exact Match), 'Between', '>'로 검색하는 범위 검색(Range) 둘 다 적합
- 트리 기반 인덱스는 검색 효율성이 높고 범위 검색이 용이하다는 장점을 갖고 있습니다. 그러나 삽입과 삭제가 빈번한 경우에는 트리의 재조정이 필요하며, 이는 성능에 영향을 미칠 수 있습니다.
* 클러스터형 인덱스
- [SQL Server]
- 클러스터형 인덱스는 해당 테이블의 레코드를 정렬된 순서로 저장하며, 이에 대한 검색 성능을 향상시킬 수 있습니다.
- 인덱스는 저장 구조에 따라 클러스터형 인덱스와 비클러스터형 인덱스로 구분
- ORACLE의 IOT와 매우 유사
- 클러스터형 인덱스의 2가지 중요성
1) 인덱스의 리프 페이지 == 데이터 페이지
-> 즉 테이블 탐색에 필요한 레코드 식별자가 리프 페이지에 없음
-> 인덱스 키 컬럼과 나머지 컬럼을 리프에 같이 저장, 테이블 랜덤 액세스 할 필요가 없음
-> 클러스터형 인덱스의 리프 페이지를 탐색하면 해당 테이블의 모든 컬럼 값 바로 얻음
2) 리프 페이지의 모든 로우(=데이터)는 인덱스 키 컬럼 순으로 물리적 정렬됨
-> 테이블 로우는 물리적으로 한 가지 순서로만 정렬될 수 있음
-> 즉, 클러스터형 인덱스는 테이블당 한 개만 생성할 수 있음
* BITMAP 인덱스
- 인덱스는 시스템에서 사용될 질의를 시스템 구현 시에 모두 알 수 없는 경우인 DW 및 AD-HOC 질의 환경을 위해서 설계되었으며, 하나의 인덱스 키 엔트리가 많은 행에 대한 포인터를 저장하고 있는 구조이다.
* 인덱스 스캔 방식 종류
- index full scan
- index range scan : 특정 범위를 스캔
- index skip scan, index fast full scan
* 전체 테이블 스캔 (FULL SCAN)
- 테이블에 존재하는 모든 데이터를 읽으면서 조건에 맞는 결과면 추출, 아니면 버리는 방식
- 시간이 매우 오래 걸림.
- ORACLE에선 테이블의 고수위 마크(HWM) 아래의 모든 블록을 읽는다.
-> 고수위 마크 : 테이블 가장 위에 있는 데이터
- 옵티마이저가 연산으로써 FULL SCAN을 선택하는 이유
1) SQL문에 조건이 존재하지 않는 경우
2) SQL문의 주어진 조건에 사용 가능한 인덱스가 존재하지 않는 경우
3) 옵티마이저의 취사 선택( = 조건을 만족하는 데이터가 많으면 대부분 블록 액세스해야됨을 판단 )
4) 그 밖에 병렬처리 방식으로 처리하는 경우
5) FULL TABLE 스캔 힌트를 사용한 경우
* 인덱스 스캔
- 인덱스의 리프 블록 = 인덱스를 구성하는 컬럼 + 레코드 식별자
-> 검색 시 인덱스 리프블록을 읽으면 이 두값을 알 수 있다.
- 인덱스는 인덱스 구성 컬럼의 순서로 정렬됨
ex) 인덱스 구성 컬럼이 A + B라면 => A컬럼으로 먼저 정렬, A값이 동일하면 B컬럼으로 정렬
* 전체 테이블스캔과 인덱스 스캔
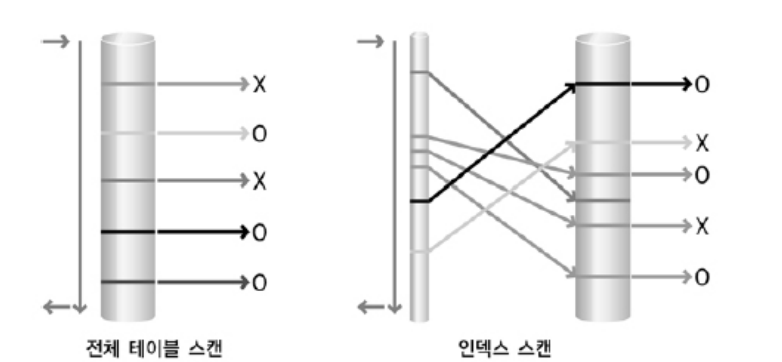
| FULL 스캔 | 인덱스 스캔 |
| 인덱스 존재 유무와 상관없이 항상 이용 가능한 방식 | 사용 가능한 적절한 인덱스가 존재할 때만 이용 가능한 방식 |
| 비효율적, 여러 블록씩 읽음, "테이블 대부분/전체 데이터 찾을 땐 유리" | 레코드 식별자 이용, 정확한 위치를 알고 있음, 한번의 I/O 요청에 한 블록씩 |
'SQLD' 카테고리의 다른 글
| SQLD 실행계획 실행순서 (0) | 2023.11.14 |
|---|---|
| SQLD 개념정리 (JOIN 수행 원리) (1) | 2023.11.14 |
| SQLD 개념정리 (절차형 SQL) (0) | 2023.11.12 |
| SQLD 개념정리 (DCL) (1) | 2023.11.12 |
| SQLD 개념정리 (윈도우 함수) (0) | 2023.11.10 |